Este artículo tratará la ciencia detrás de las recomendaciones de música personalizadas.
Empezaremos por Discover Weekly. Un mixtape personalizado de 30 canciones que nunca han escuchado antes pero que probablemente les encantará, y tiene bastante de «mágico».
Muchas personas son grandes fans de Spotify, y particularmente de Discover Weekly. ¿Por qué? Porque conoce sus gustos musicales mejor que nadie. Las canciones que se encuentran les encantan y probablemente, de no ser por la recomendación nunca hubieran encontrado.
Dicho esto, vamos con tu mejor amigo virtual: Discover Weekly.
Discover Weekly
El gran éxito de esta playlist está sustentado por una gran base de usuarios que se vuelve loca por ello, lo que ha llevado a Spotify a repensar su enfoque e invertir más recursos en listas de reproducción basadas en algoritmos.
Desde que Discover Weekly debutara en 2015, muchos se mueren por saber cómo funciona.
Entonces, ¿cómo hace Spotify un trabajo tan increíble al elegir esas 30 canciones para cada persona cada semana? Alejémonos por un segundo para ver cómo otros servicios de música han abordado las recomendaciones de música y cómo Spotify lo está haciendo mejor.
Breve Historia sobre la Curación de Música
En la década de 2000, Songza inició la curación de música en línea utilizando la curación manual para crear listas de reproducción para los usuarios. Esto significaba que un equipo de «expertos en música» u otros curadores humanos reunirían listas de reproducción que pensaban que sonaban bien, y luego los usuarios escuchaban esas listas de reproducción. (Más tarde, Beats Music emplearía esta misma estrategia). La curación manual funcionó bien, pero se basó en las elecciones específicas de ese curador y, por lo tanto, no pudo tomar en cuenta el gusto musical individual de cada oyente.
Como Songza, Pandora también fue uno de los players originales en la curación de música digital. Se empleó un enfoque un poco más avanzado, en lugar de etiquetar manualmente los atributos de las canciones. Esto significó que un grupo de personas escuchó música, eligió un montón de palabras descriptivas para cada pista y etiquetó las pistas en consecuencia.
Luego, el código de Pandora podría simplemente filtrar ciertas etiquetas para hacer listas de reproducción de música de sonido similar. Alrededor de ese mismo tiempo, nació una agencia de inteligencia musical del MIT Media Lab llamada The Echo Nest, que adoptó un enfoque radical y de vanguardia para la música personalizada. Echo Nest utilizó algoritmos para analizar el contenido de audio y texto de la música, lo que le permite realizar la identificación de la música, la recomendación personalizada, la creación de listas de reproducción y el análisis.
Finalmente, otro enfoque es Last.fm, que todavía existe hoy en día y utiliza un proceso llamado filtrado colaborativo para identificar la música que a sus usuarios les gustaría, pero hablaremos más sobre eso en un momento.
Entonces, si así es como otros servicios de curación de música han manejado las recomendaciones, ¿cómo funciona el motor mágico de Spotify? ¿Cómo parece satisfacer los gustos de los usuarios de forma mucho más precisa que cualquiera de los otros servicios?
Los Tres Tipos de Modelos de Recomendación de Spotify
Spotify no usa un único modelo de recomendación. En su lugar, combinan algunas de las mejores estrategias utilizadas por otros servicios para crear su propio motor de descubrimiento único y poderoso.
Para crear Discover Weekly, hay tres tipos principales de modelos de recomendación que emplea Spotify:
- Modelos de filtrado colaborativo (es decir, los que Last.fm usó originalmente), que analizan su comportamiento y el comportamiento de los demás.
- Modelos de Procesamiento de Lenguaje Natural (En inglés NLP; Natural Language Processing), que analizan texto.
- Modelos de audio, que analizan las pistas de audio en bruto.

Veamos cómo funciona cada uno de estos modelos de recomendación
Modelo de Recomendación 1. Filtrado Colaborativo
Primero, algunos antecedentes: cuando las personas escuchan las palabras «filtrado colaborativo», generalmente piensan en Netflix, ya que fue una de las primeras compañías en usar este método para impulsar un modelo de recomendación, tomando las calificaciones de películas basadas en estrellas de los usuarios para informar qué películas recomendar a otros usuarios similares.
Después de que Netflix tuvo éxito, el uso del filtrado colaborativo se extendió rápidamente, y ahora es a menudo el punto de partida para cualquiera que intente hacer un modelo de recomendación.
A diferencia de Netflix, Spotify no tiene un sistema basado en estrellas con el que los usuarios califiquen su música. En cambio, los datos de Spotify son retroalimentación implícita, específicamente, la cantidad de pistas y los datos de transmisión adicionales, como por ejemplo, si un usuario guardó la pista en su propia lista de reproducción o visitó la página del artista después de escuchar una canción.
Pero, ¿qué es realmente el filtrado colaborativo y cómo funciona? Aquí hay un resumen de alto nivel, explicado en una conversación rápida:
«¡Ey, me gustan las pistas P, Q, R y S!»
«¡Bueno, a mí me encantan Q, R, S y T!»
«¡Entonces deberías escuchar P ya mismo!»
«¡Vale, y tú deberías escuchar Q!
¿Qué está pasando aquí? Cada uno de estos individuos tiene preferencias de pistas: la de la izquierda le gusta a las pistas P, Q, R y S, mientras que la de la derecha le gusta a las pistas Q, R, S y T.
El filtrado colaborativo luego usa esos datos para decir:
«Hmmm … A los dos les gustan tres de las mismas pistas, Q, R y S, por lo que probablemente sean usuarios similares. Por lo tanto, es probable que cada uno disfrute de otras pistas que la otra persona ha escuchado, que aún no ha escuchado”.
Por lo tanto, sugiere que el que está en la pista de salida P de la derecha – la única pista no mencionada, pero que disfrutó de su contraparte «similar» – y el de la pista de salida T de la izquierda, por el mismo razonamiento. Simple, ¿verdad?
Pero, ¿cómo utiliza Spotify ese concepto en la práctica para calcular las pistas sugeridas por millones de usuarios en función de las preferencias de millones de otros usuarios?
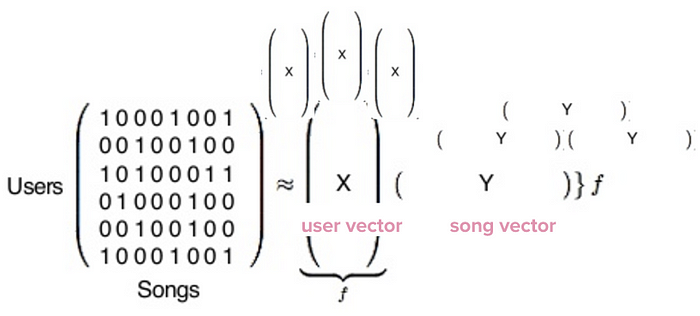
Con matemáticas, hecho con bibliotecas de Python

En realidad, esta matriz que ves aquí es gigantesca. Cada fila representa uno de los 140 millones de usuarios de Spotify (si usas Spotify, tu mismo eres una fila en esta matriz) y cada columna representa una de las 30 millones de canciones en la base de datos de Spotify.
Después, la biblioteca de Python ejecuta esta fórmula de factorización de matriz larga y complicada:

Cuando termina, terminamos con dos tipos de vectores, representados aquí por X e Y. X es el vector usuario, que representa el gusto de un solo usuario, e Y es un vector de canción, que representa el perfil de una sola canción.
Ahora tenemos 140 millones de vectores de usuario y 30 millones de vectores de canciones. El contenido real de estos vectores es solo un montón de números que esencialmente no tienen significado por sí mismos, pero son enormemente útiles cuando se comparan.
Para saber qué gustos musicales de los usuarios son más similares a los nuestros, el filtrado colaborativo compara nuestro vector con todos los vectores de los demás usuarios, y finalmente revela qué usuarios son los más cercanos. Lo mismo ocurre con el vector Y, canciones: puede comparar el vector de una sola canción con todos los demás, y descubrir qué canciones son más similares a la que se trata.
El filtrado colaborativo hace un buen trabajo, pero Spotify sabía que podrían hacerlo aún mejor al agregar otro motor: PNL.
Modelo de Recomendación 2. Procesamiento de Lenguaje Natural (PLN)
El segundo tipo de modelos de recomendación que emplea Spotify son los modelos de procesamiento en lenguaje natural (PLN). Los datos de origen de estos modelos, como sugiere su nombre, son palabras habituales: rastrear metadatos, artículos de noticias, blogs y otro texto en Internet.
El procesamiento del lenguaje natural, que es la capacidad de una computadora para entender el habla humana como se habla, es un vasto campo en sí mismo, a menudo aprovechado a través de las API de análisis de sentimientos.
Los mecanismos exactos detrás de la PLN están más allá del alcance de este artículo, pero esto es lo que sucede en un nivel muy alto: Spotify rastrea la web constantemente en busca de publicaciones de blog y otros textos escritos sobre música para descubrir qué dice la gente sobre artistas y canciones específicas. – qué adjetivos y qué lenguaje en particular se usa frecuentemente en referencia a esos artistas y canciones, y qué otros artistas y canciones también se están discutiendo junto a ellos.
Si bien no se conocen de forma pública los detalles específicos de cómo elige Spotify para luego procesar estos datos, si podemos, por otro lado, hacernos una idea de cómo funcionaba Echo Nest para trabajar con ellos. Agruparían los datos de Spotify en lo que denominan «vectores culturales» o «términos principales». Cada artista y canción tenían miles de términos principales que cambiaron en el diario. Cada término tenía un peso asociado, que se correlacionaba con su importancia relativa: aproximadamente, la probabilidad de que alguien describa la música o el artista con ese término.
Luego, al igual que en el filtrado colaborativo, el modelo de la PLN usa estos términos y pesos para crear una representación vectorial de la canción que se puede usar para determinar si dos piezas de música son similares. Genial, ¿verdad?
Modelo de Recomendación 3. Modelos de Audio sin Procesar
Primero, una pregunta. Podrías estar pensando: Ey, pero ya tenemos muchos datos de los dos primeros modelos! ¿Por qué necesitamos también analizar el audio en sí mismo?
En primer lugar, agregar un tercer modelo mejora aún más la precisión del servicio de recomendación de música. Pero este modelo también tiene un propósito secundario: a diferencia de los dos primeros tipos, los modelos de audio en bruto tienen en cuenta las nuevas canciones.
Toma, por ejemplo, una canción que tu amigo cantante y compositor ha puesto en Spotify. Tal vez solo tiene 50 reproducciones, por lo que hay algunos otros oyentes contra los que filtrar en colaboración. Tampoco se menciona en ninguna parte de Internet, por lo que los modelos de PLN no lo detectan. Afortunadamente, los modelos de audio en bruto no distinguen entre pistas nuevas y pistas populares, por lo que con su ayuda, la canción de tu amigo podría terminar en una lista de reproducción de Discover Weekly junto a canciones populares.
Pero, ¿cómo podemos analizar los datos de audio en bruto, que parece tan abstracto?
Con redes neuronales convolucionales
Las redes neuronales convolucionales son la misma tecnología utilizada en el software de reconocimiento facial. En el caso de Spotify, se han modificado para su uso en datos de audio en lugar de píxeles. Aquí hay un ejemplo de una arquitectura de red neuronal:
Esta red neuronal particular tiene cuatro capas convolucionales, vistas como barras gruesas a la izquierda, y tres capas densas, vistas como barras más estrechas a la derecha. Las entradas son representaciones tiempo-frecuencia de cuadros de audio, que luego se concatenan, o se unen entre sí, para formar el espectrograma.
Los cuadros de audio pasan por estas capas convolucionales y, después de pasar por la última, se puede ver una capa de «agrupación temporal global», que se agrupa en todo el eje de tiempo, calculando de manera efectiva las estadísticas de las características aprendidas a lo largo de la canción.
Después del procesamiento, la red neuronal devuelve un entendimiento de la canción, que incluye características como el tiempo estimado, la clave, el modo, el tempo y el volumen. A continuación se muestra un gráfico de datos de un fragmento de 30 segundos de «Around the World» de Daft Punk.

En última instancia, esta lectura de las características clave de la canción le permite a Spotify comprender las similitudes fundamentales entre las canciones y, por lo tanto, qué usuarios podrían disfrutarlas, en función de su propio historial de escucha.
Y así hemos cubierto los conceptos básicos de los tres tipos principales de modelos de recomendación que alimentan el Pipeline de Recomendaciones de Spotify, y finalmente impulsan la lista de reproducción de Discover Weekly.

Por supuesto, estos modelos de recomendación están todos conectados al ecosistema más grande de Spotify, que incluye enormes cantidades de almacenamiento de datos y utiliza muchos clusters de Hadoop para escalar las recomendaciones y hacer que estos motores funcionen en enormes matrices, interminables artículos de música en línea y una enorme cantidad de archivos de audio. .
Espero que esto haya sido informativo y haya despertado tu curiosidad. Por ahora, trabajen en sus propios Discover Weekly, encontrando nueva música favorita mientras aprecias todo el aprendizaje de máquina que está ocurriendo tras bastidores.
¿Te gustó el artículo?

 (11 Votos, Promedio: 4,82 de 5)
(11 Votos, Promedio: 4,82 de 5)